background
I am a Post-doctoral Fellow for the Strategic Data Project at the Center for Education Policy Research. Through that appointment, I am the Director of Data Science at the national grant-making non-profit, Accelerate. Before that, I received my PhD in English and Education from University of Michigan.
My research relevant to AI and Assessment has three on-going avenues. Because individual speaking time is short, and discussion time is long. I aim for breadth rather than depth, hoping you’ll find at least one area of overlapping interest.
Do standardized essay tests accurately predict college-level writing ability?
In the U.S., many colleges use standardized test scores like the ACT, SAT, or AP exams to place first-year students into writing courses, give them credit, or let them skip composition classes. Over 2,000 schools have these policies, but research shows little connection between test-based writing skills and actual college writing. This study looks at 47,000 student essays and their test scores to see if high scores mean students write in noticeably different ways. Using AI models like BERT, RoBERTa, and XLNet, the study finds only a weak link between test scores and college writing. Higher-scoring students tend to use fewer clauses per sentence and more prepositions, adverbs, colons, and adjectives, but these differences are small. A policy that sorts students by a single test score is less useful than one based on multiple measures. Overall, the study suggests that standardized tests do not strongly predict how well students will write in college and may not be a good way to guide educational policy.
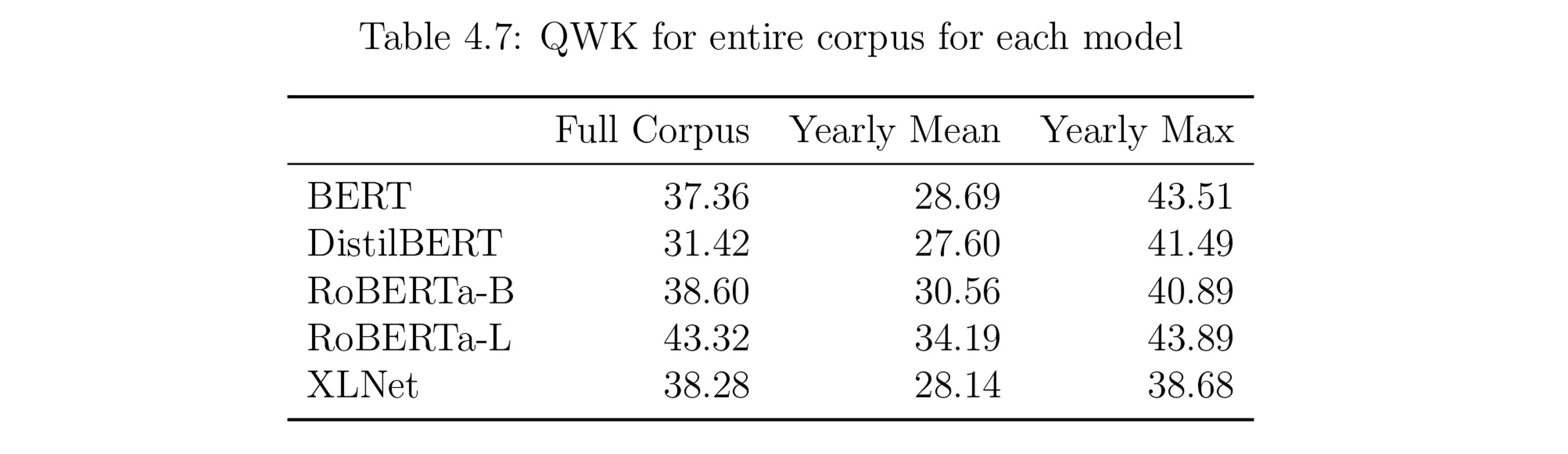
The figure below shows the final Quadratic Weighted Kappa scores for the most performant hyperparameters of the most performant models. The scores are weak to minimal, as defined by best practices.
Can we use LLMs to generate a corpus of student-level writing?
Generating simulated student writing presents significant challenges, as highlighted in recent research 1 2 3. Existing approaches primarily rely on prompting large language models (LLMs) to generate essays without reference texts, limiting their alignment with authentic student writing. This project seeks to develop a simulated corpus in which each generated essay corresponds 1:1 with an actual student essay, maintaining linguistic similarity while ensuring that no named entities or n-grams of length < 3 remain intact.
As part of an NSF-funded initiative in collaboration with the University of Michigan’s LAUNCH Lab, this work aims to create a corpus that preserves linguistic characteristics of student writing while safeguarding privacy and intellectual property. The ultimate goal is to produce a resource sufficiently distinct from its source texts to mitigate risks of re-identification, yet valuable for researchers studying student writing. Ideally, this corpus could serve as an addendum to the MICUSP corpus, though further development is required to achieve this vision.
Do any AI tutoring products rival human-delivered High Dosage Tutoring in impact while improving scalability and reducing costs?
This is something I’m looking into as part of my post doctorate. Let me know if you have any leads. Must be working in the K12 space, in more than 2 schools or districts, and have on-going implementations of at least 600 students in any given semester.
They don’t need to have a completed impact study, but they need to be amenable to having one done by a third party who would publish the report regardless of results.